
Large Language Models are the hottest topic in the localization industry today. While some Natural Language Processing (NLP) tools are suitable for some languages, many are not sufficiently trained for Arabic localization, which presents unique and complex challenges that stretch their current capabilities.
Despite having a massive base of +400 million speakers worldwide (spanning the Arab world and other regions, being the official language in more than 26 nations, and having an extensive literary history), Arabic often acts like a language with limited resources when training LLMs for tasks like localization.
This isn't because Arabic text is scarce, but rather due to a mix of linguistic, cultural, and technical issues that make it difficult to generate the data LLMs need to function effectively. That’s why Arabic is considered a low-resource language.
Despite being spoken by 400+ million people worldwide, Arabic often acts as a low-resource language for LLMs. This isn't because Arabic text is scarce, but rather because the mix of linguistic, cultural, and technical issues makes it difficult to generate the data needed
However, because of the current improvements, a light at the end of the seemingly dark tunnel can be seen. Could LLMs improve exponentially to be able to tackle Arabic? We'll explore this in the article — but first, let's find out why Arabic is so hard to translate for them.

📜 Why is Arabic considered low-resource for LLMs? 🔗
There are a few good reasons behind Arabic being considered a low-resource language. They include factors from dialect differences to complicated morphology and its unique script.
Dialects & variations 🔗
Arabic exhibits diglossia, meaning it has two forms: Modern Standard Arabic (MSA) for formal use and numerous spoken dialects for daily communication. 🗣️ While MSA text is plentiful, most online content, particularly informal content, uses dialects.
LLMs trained mainly on MSA struggle with these dialects, which are essential for effective localization in fields like marketing, social media, and entertainment. The issue is worsened by the scarcity of transcribed and labeled data for these dialects, making it hard to train LLMs on them.
Arabic dialects aren't a single, uniform language. Some are mutually unintelligible, like Egyptian, Levantine, Gulf, and Maghrebi Arabic. Spoken Arabic isn't uniform across countries either; it varies regionally. Dialects are further shaped by differences between urban and rural areas and by the impact of foreign languages like French or English. You can think of Arabic and dialects as a sea full of different types of fish. They are all fish, but they are distinct. 🐟
This dialectal variation makes it difficult to apply insights or models trained on one dialect to another, since LLMs usually learn from large, general datasets. Because of the complexity of dealing with numerous dialects and the differences between formal and informal language, the abundance of available Arabic data doesn't translate to easy or effective processing for LLMs.
👋 For instance, a simple word like "Hello" could be written as "مرحبًا" in MSA, but might appear as "عالسلامة" in Tunisian Arabic or "أهلين" in Levantine Arabic
Complex morphology 🔗
Arabic's complex morphology, where words change form significantly through prefixes, suffixes, infixes, and root patterns, presents a challenge for LLMs. 🔍 This rich system of word formation, with a single root potentially generating hundreds of different words, adds to the language's complexity for AI.
Arabic words frequently stem from a root system, typically three consonants, which form the base meaning. Various patterns of vowels, prefixes, and suffixes are then added to this root to create words with related but distinct meanings.
🎨 For example, the root "r-s-m" (paint) gives rise to "rassam" (painter), and "rasama" (he painted). This rich morphology, however, creates ambiguity
Because vowels are often left out in written Arabic, a single word can have multiple interpretations, making it difficult for models to understand the correct meaning within a given context.
This intricate system makes things even harder for LLMs. They not only have to grasp the root system but also figure out the correct meaning from the context, a process that demands significantly more computing power and advanced model design than current LLMs often possess.
Script and orthography 🔗
The Arabic script itself presents further hurdles for LLMs. Its right-to-left direction and other unique features set it apart from Latin-based scripts. One key challenge is diacritics: these marks clarify pronunciation and distinguish words, but are frequently omitted in standard writing, creating ambiguity.
👨🎨 For instance, the painted form "رسم" could mean "he painted" (rasama), or "paint" (rasm), depending on the unwritten diacritics. Also, the way Arabic word endings change based on grammar (like case markers) means a single root can have many different forms

These linguistic features pose specific architectural challenges for LLMs. Standard tokenization methods, often designed for languages like English, aren't well-suited for Arabic. Because Arabic words are built from roots, splitting them into subwords (a common LLM practice) can obscure important semantic links.
In practice, this means that breaking down words from the root "ر-س-م" (r-s-m), such as "رسم" (paint), "رسام" (painter), and "مرسم" (studio), can make it harder for the model to recognize the shared meaning related to "painting."
Data scarcity and imbalance 🔗
Despite its large speaker base, Arabic lacks the rich and varied datasets needed for training effective LLMs, especially compared to languages like English. This data scarcity presents several problems:
- 🏷️ First, there's a shortage of annotated data for supervised tasks like sentiment analysis, named entity recognition, and translation. The data that does exist often focuses on MSA rather than the more commonly used dialects and informal language.
- 🩺 Second, there are gaps in specific areas. Arabic datasets often underrepresent certain regions and specialized fields like medicine or law, hindering a model's ability to perform well in those contexts.
This data scarcity creates a vicious cycle. Limited training data results in less effective models, which discourages the use of Arabic language technology. This lack of adoption, in turn, reduces the incentive to invest in better Arabic language support, perpetuating the data shortage.
Design challenges 🔗
Arabic's right-to-left writing system requires more than just text translation; it demands a complete redesign of user interfaces. This includes mirroring elements like menus, buttons, text, and images. While LLMs don't manage these layout changes, their output needs to fit well into these reversed interfaces and adapt to specific cultural preferences.
Visual elements like colors and images must be carefully chosen to resonate with the target audience. Achieving this requires tight cooperation between language experts, designers, and developers, significantly increasing the complexity of localization.
🤖 Testing 8 LLMs on Arabic translation 🔗
The Arabic language AI technology is promising, but it is developing slowly. The attempts to push further its emerging potential are faced with new ongoing hurdles. These systems have certainly advanced, yet they remain works in progress rather than final answers to Arabic natural language processing needs — especially when localizing content for Arabic-speaking users.
Current Arabic-capable models demonstrate varied capabilities: some excel at formal text generation while stumbling with dialectal variations; others handle basic translation effectively but falter when it comes to cultural nuances.
The technology shows promise in structured contexts like information retrieval and straightforward content creation, but requires human oversight for tasks demanding cultural sensitivity or technical precision. Here's a summary of some Arabic LLMs' current state, capabilities, strengths, and weaknesses.
1. GPT-4 (multilingual model) 🔗
GPT-4 works across multiple languages, including Arabic, with the ability to process and produce text in over 25 languages. The model demonstrates proficiency in generating well-structured sentences in Modern Standard Arabic (MSA) while offering some capability to handle various Arabic dialects.
It serves effectively for conversational tasks, making it suitable for customer support, casual interactions, and information retrieval in Arabic. Also, it provides reasonable translation services between Arabic and other languages, particularly when working with MSA rather than dialectal variants.
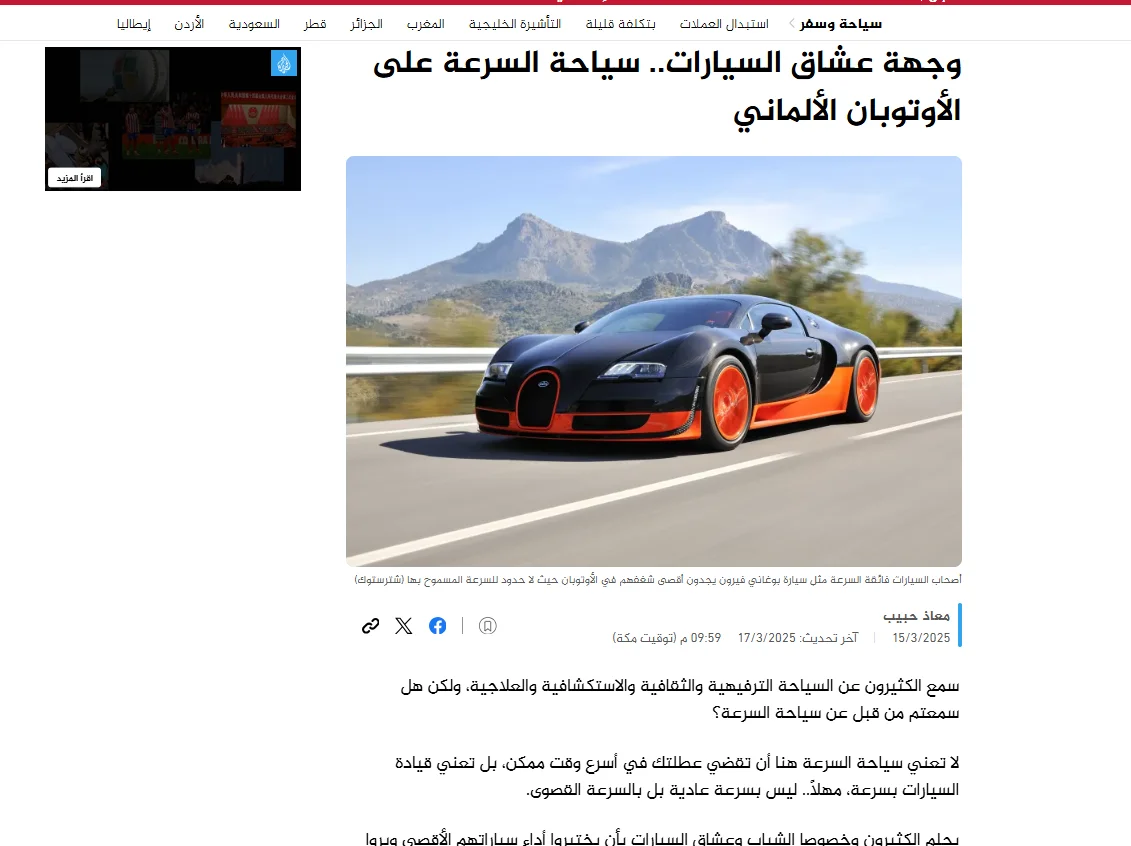
The following prompt asks for the translation of يا مساء الزبادي, an informal way to say "good evening" in Egyptian Arabic. The translation is literal and doesn’t convey the playfulness of the greeting:

- Demonstrates a good general understanding of MSA and some Arabic dialects.
- Capable of generating creative content in Arabic, such as short stories, articles, and poetry.
- Maintains contextual coherence in responses, correctly using grammatical elements like tense and subject-object agreement.
- Has difficulty with dialectal Arabic. For example, it might misinterpret an Egyptian Arabic phrase or translate it into MSA, losing the intended regional meaning.
- Struggles with informal, slang-filled Arabic speech.
- May misinterpret or create ambiguous words due to the common omission of vowels in written Arabic, which can lead to multiple meanings.
2. Claude 🔗
Claude understands Modern Standard Arabic (MSA) texts accurately and handles complex Arabic grammar correctly. It processes sentence structures, word forms, and language features properly. The model works consistently well with different types of Arabic text, including those with challenging grammar elements like dual forms and verb patterns.
Here is an example in which Claude explains the translation and the meaning of the sentence:

- It performs well in academic and formal settings.
- Sometimes it misses cultural nuances.
- Struggles with dialect-specific expressions.
- Might produce unnatural-sounding responses in casual conversations.
- Shows inconsistency in technical terminology, potentially mixing Arabic terms and English loanwords.
Apart from global, Western models like ChatGPT and Claude, there are several emerging models that focus exclusively on Arabic localization. Some of these AI tools, designed with cultural and linguistic sensitivity, can leverage 'pronoia' to cultivate positive communication. This means that translations and content are accurate and intentionally crafted to resonate with users on a deeper level. Let's see how they fared in our analysis next.
3. Jais 🔗
Jais, released by Inception in 2023, was trained on 116 billion Arabic tokens and 279 billion English data tokens. It excels at text generation, creating natural-sounding articles, reports, and stories in Arabic. It is capable of generating natural Arabic text, sentiment analysis, summarization, Named Entity Recognition, and Arabic-English translation. Also, it performs well in machine translation between Arabic and other languages.
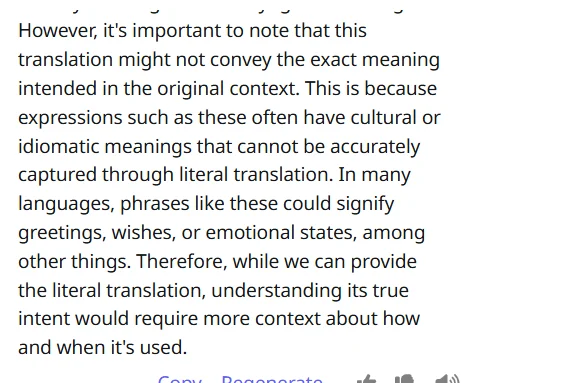
Let's use the same example of مساء الزبادي that we used for ChatGPT. We see that it fails, as it doesn't convey the playfulness of the expression. It says that the translation is literal and needs more context:

- It was trained explicitly on Arabic data, providing a deep understanding of MSA and regional dialects.
- Highly effective in tasks like text summarization and sentiment analysis for formal Arabic.
- Designed for business integration: it offers document automation and customer service (chatbots).
- Still struggles with understanding and generating content in various regional Arabic dialects.
- Tends to produce formal MSA, limiting its usefulness for informal applications.
- May generate content lacking natural flow or authenticity in creative tasks.
4. Tarjama's Arabic Machine Translation (AMT) 🔗
Tarjama's Arabic Machine Translation (AMT) system offers business-focused translations with a focus on accuracy and security. One of its strengths is that it maintains original document formatting and complies with ISO 27001 standards. AMT can be customized using client-specific data for enhanced precision and uses advanced technology for Arabic translation.
The following example is about a proverb coined to indicate the extent of similarity and identity between a mother and her daughter. Regardless of getting a literal translation, it couldn’t differentiate between two Arabic words without diacritics:

- Trained on curated, high-quality data, which contributes to its accuracy.
- Handles domain-specific terminology (legal, financial, healthcare, etc.).
- Integrates into existing workflows, supporting various document formats.
- Incorporates a Human-in-the-Loop approach.
- Adheres to ISO 27001 standards.
- Highly specialized jargon may require human review.
- Some idiomatic or culturally specific references may need post-editing.
5. Alibaba Cloud's Qwen Series (Qwen 1.5 & Qwen 2) 🔗
Alibaba Cloud's Qwen series, including versions 1.5 and 2, supports over 29 languages including Arabic. It performs well in transcribing and translating, improving speech translation.
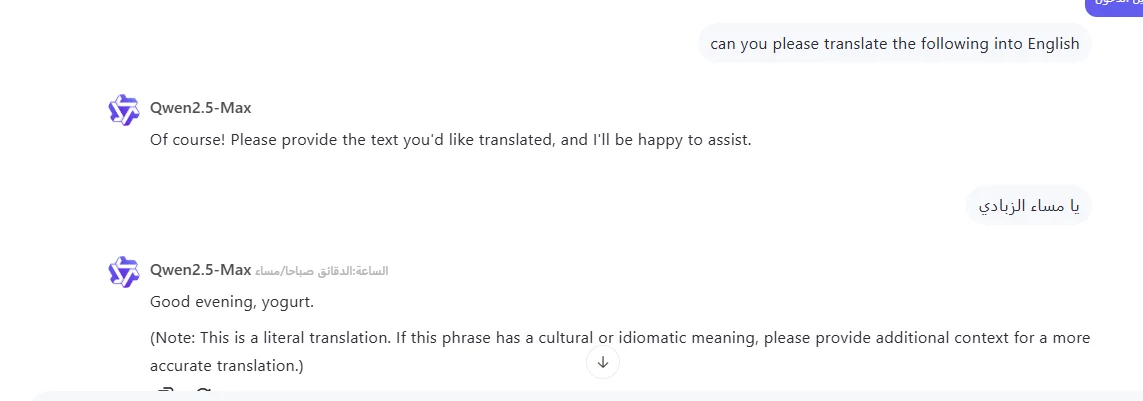
Here is a translation example from Qwen where we can see it struggled with context and cultural accuracy:
- Supports 29 languages, including Arabic.
- Offers a cost-effective alternative to human translation.
- May struggle with cultural nuances and idiomatic expressions.
- May encounter challenges with specialized or technical jargon.
- Can face difficulties in comprehending larger or implicit contexts.
6. AraBERT 🔗
AraBERT was specifically designed for the Arabic language based on Google's BERT architecture. It does a great job in tasks like Named Entity Recognition (NER), part-of-speech tagging, sentiment analysis, and text classification.
Now, let's test this model with this source text:
"This product will revolutionize the industry."
AraBERT’s Target: "سوف تحدث هذه المنتجات ثورة في الصناعة."
Here, we run into an incorrect word choice or mistranslation. The phrase "سوف تحدث هذه المنتجات ثورة" translates to "these products will revolutionize." However, the original source talks about a singular "product," so the plural form ("المنتجات") would be a meaning error.
The correct translation should be "سوف تحدث هذه المنتج ثورة في الصناعة."
- Efficient for formal MSA.
- Performs well on document classification, summarization, and question answering.
- Poor performance with Arabic dialects.
- Weak in creative text generation and complex conversations.
7. CAMeL (CAMeL Lab’s Arabic Models) 🔗
CAMeL Lab's Arabic models specialize in various dialects: Gulf, Levantine, Egyptian, and Maghrebi. Their suite of tools, known as CAMeL Tools, offers functionalities like pre-processing, morphological modeling, dialect identification, named entity recognition, and sentiment analysis.
What about a translation example? Let's have a look at it.
We will use this source text: "The match was a real game-changer."
CAMel’s target translation: "كانت المباراة مغيرة حقيقية للعبة."
We run into a literal translation of an idiomatic expression. The phrase "game-changer" is a colloquial expression in English, meaning something that changes the course of an event or situation. CAMeL could have translated this literally as "مغيرة حقيقية للعبة," which would not convey the idiomatic meaning correctly.
A better and more accurate translation here would be: "كانت المباراة نقطة تحول حقيقية."
- Fine-tuned for dialectal Arabic.
- Handles sentiment analysis and code-switching.
- Difficulties with contextual coherence in longer texts, especially mixed MSA and dialects.
- Struggles with highly informal or niche contexts due to being trained on limited data.
8. Tashkeela (QCRI) 🔗
Qatar Computing Research Institute's (QCRI) Tashkeela AI model adds diacritical marks to Arabic text and performs Named Entity Recognition (NER) and other Natural Language Processing tasks in MSA. It features a corpus of 75 million fully vocalized words from 97 classical and modern Arabic books, which made possible the development of diacritization systems.
Here is an example of using Tashkeela to add diacritization to Arabic texts to make them clearer:
- Arabic text without diacritics:
"ذهب الولد إلى المدرسة" - Arabic text with diacritics:
"ذَهَبَ اَلْوَلَدُ إِلَى اَلْمَدْرَسَةِ" - English translation:
"The boy went to school."
Note: This model is used to add diacritics to clarify the meaning and provide an accurate translation. It doesn't provide translation. Its accuracy is continuously increasing, becoming more and more reliable.

- It reduces ambiguity through diacritics.
- With a focus on MSA, it performs well with standardized Arabic.
- Struggles with non-standard Arabic.
- Since it's limited to diacritics, it offers limited utility for deeper text understanding or generation.
☝️ My picks as a translator 🔗
Although all models are still a work in progress, Claude is my personal pick for Arabic localization tasks. The LLM by Anthropic is advancing constantly — it understands cultural references and considers the nuances of the language. It can also:
- 🚩 Detect literal translation and help revise long texts, suggesting better options when asked.
- ✏️ Help with different types of content, providing accurate equivalents, and considering context.
- 💬 Remind the user of the different word meanings that could be used depending on the context.
For simple translation, ChatGPT is also a good option, considering how it understands different dialects. It can help identify the nature of the source and suggest a suitable translation. However, it might skip some paragraphs or lines.
Finally, AMT and Qwen are suitable options if you're dealing with business and customer service-related content, but keep in mind that they don't always get dialects correctly. They are progressing, but until now, I haven't found a better option than Claude.
🎙️ How realistic are agentic workflows in localization, and are we ready to implement them? Listen to our Bridging the Gap podcast episode with Julia Díez for a deep dive into it.
🤷 Can AI deal with my Arabic content? 🔗
Now, you might ask, "How can I know if the LLM I use suits my content translation needs?". Well, that's a fair question. Here are some factors you should take into consideration to assess this:

1. Industry specificity 🔗
Check if the model is trained on domain-specific data (legal, medical, etc.) and if your content is technical/specialized. You need to determine how standardized the terminology is.
2. Target audience/region 🔗
Ensure the model handles dialectal variations (Egyptian, Gulf, etc.). Check which Arabic variants are used and if there are multiple dialects needed or a required formality level.
3. User experience 🔗
Verify contextual relevance and coherent dialogue in conversations.
4. Informal/social media language 🔗
If your content includes more informal language, check how the model handles slang, abbreviations, and code-switching.
5. Nuanced sentiment analysis 🔗
Test how the LLM handles complex emotions, like sarcasm and ambiguity.
6. Undiacritized Arabic 🔗
Test the model's ability to handle text without vowel markings.
7. Multilingual/code-switched content 🔗
Check for fluid language switching and bilingual content processing.
8. Content format/style variability 🔗
Ensure the model handles different registers and contexts.
9. Real-time processing 🔗
For time-sensitive applications, evaluate processing times of the different options.
10. Accuracy vs. functionality 🔗
Determine the required accuracy level for your specific use case.
11. Performance evaluation 🔗
Monitor overall tendencies like accuracy, dialect handling, and technical term consistency.
12. Error analysis 🔗
Finally, document dialect mismatches, technical term confusion, formality issues, and cultural misunderstandings. Evaluate error significance (safety, brand, user experience, legal). Decide how much human oversight is needed.
13. Final check: sample data testing 🔗
Crucially, always test with real sample data to identify specific strengths and weaknesses. Create representative samples with dialects, technical terms, formality variations, numbers, and dates.
After considering all of these aspects, you can go ahead and use the AI model of your choice for a while to see how it performs. But if you're still unsure about using AI in your industry, this would be a quick and brief categorization that tells you if it would make sense to use AI in your industry or not:
- 🟢 Safe for AI: General MSA information, basic queries, non-critical content, and standard communication.
- 🟠 Requires careful monitoring: Mixed dialects, semi-technical documentation, marketing, education.
- 🔴 Not ready for AI: Legal documents, medical instructions, safety-critical information, creative content, and complex manuals.
👀 Conclusion: Is it worth it to use AI to localize to Arabic? 🔗
AI is a valuable assistant for Arabic content, but has limitations. It still makes mistakes regardless of what model you choose, especially when the material is nuanced and contains specialized vocabulary.
Arabic's complexity requires contextual understanding that AI alone cannot fully provide. While AI can translate and generate content to some point, human oversight is what controls the cultural relevance, proper right-to-left layouts, and brand alignment. Dialectal Arabic particularly challenges AI systems, often necessitating human adaptation.
Critical documents like legal or medical texts absolutely require human review. If you're dealing with that type of sensitive material (or with technical or very nuanced content in Arabic), proofreading is still highly important. We're here to help — get in touch with expert Arabic translators from our Continuous Localization Team, or begin experimenting with Localazy on your own for your Arabic-speaking projects.



